Sunday, June 29, 2008
HGP - Benefits
Benefits
The work on interpretation of genome data is still in its initial stages. It is anticipated that detailed knowledge of the human genome will provide new avenues for advances in medicine and biotechnology. Clear practical results of the project emerged even before the work was finished. For example, a number of companies, such as Myriad Genetics started offering easy ways to administer genetic tests that can show predisposition to a variety of illnesses, including breast cancer, disorders of hemostasis, cystic fibrosis, liver diseases and many others.
Also, the etiologies for cancers, Alzheimer's disease and other areas of clinical interest are considered likely to benefit from genome information and possibly may lead in the long term to significant advances in their management.
There are also many tangible benefits for biological scientists. For example, a researcher investigating a certain form of cancer may have narrowed down his/her search to a particular gene. By visiting the human genome database on the world wide web, this researcher can examine what other scientists have written about this gene, including (potentially) the three-dimensional structure of its product, its function(s), its evolutionary relationships to other human genes, or to genes in mice or yeast or fruit flies, possible detrimental mutations, interactions with other genes, body tissues in which this gene is activated, diseases associated with this gene or other datatypes.
Further, deeper understanding of the disease processes at the level of molecular biology may determine new therapeutic procedures. Given the established importance of DNA in molecular biology and its central role in determining the fundamental operation of cellular processes, it is likely that expanded knowledge in this area will facilitate medical advances in numerous areas of clinical interest that may not have been possible without them.
The analysis of similarities between DNA sequences from different organisms is also opening new avenues in the study of the theory of evolution. In many cases, evolutionary questions can now be framed in terms of molecular biology; indeed, many major evolutionary milestones (the emergence of the ribosome and organelles, the development of embryos with body plans, the vertebrate immune system) can be related to the molecular level.
Many questions about the similarities and differences between humans and our closest relatives (the primates, and indeed the other mammals) are expected to be illuminated by the data from this project.
The Human Genome Diversity Project (HGDP), spinoff research aimed at mapping the DNA that varies between human ethnic groups, which was rumored to have been halted, actually did continue and to date has yielded new conclusions.[citation needed] In the future, HGDP could possibly expose new data in disease surveillance, human development and anthropology. HGDP could unlock secrets behind and create new strategies for managing the vulnerability of ethnic groups to certain diseases (see race in biomedicine). It could also show how human populations have adapted to these vulnerabilities.
The Human Genome Project
The Human Genome Project
The Human Genome Project (HGP) was an international scientific research project with a primary goal to determine the sequence of chemical base pairs, which make up DNA and to identify the approximately 25,000 genes of the human genome from both a physical and functional standpoint.
The project began in 1990 initially headed by James D. Watson at the U.S. National Institutes of Health. A working draft of the genome was released in 2000 and a complete one in 2003, with further analysis still being published. A parallel project was conducted by the private company Celera Genomics. Most of the sequencing was performed in universities and research centers from the United States, Canada and Great Britain. The mapping of human genes is an important step in the development of medicines and other aspects of health care.
While the objective of the Human Genome Project is to understand the genetic makeup of the human species, the project also has focused on several other nonhuman organisms such as E. coli, the fruit fly, and the laboratory mouse. It remains one of the largest single investigational projects in modern science.[citation needed].
The HGP originally aimed to map the nucleotides contained in a haploid reference human genome (more than three billion). Several groups have announced efforts to extend this to diploid human genomes including the International HapMap Project, Applied Biosystems, Perlegen, Illumina, JCVI, Personal Genome Project, and Roche-454.
The "genome" of any given individual (except for identical twins and cloned animals) is unique; mapping "the human genome" involves sequencing multiple variations of each gene. The project did not study the entire DNA found in human cells; some heterochromatic areas (about 8% of the total) remain un-sequenced.
History
In 1976, the genome of the virus Bacteriophage MS2 was the first complete genome to be determined, by Walter Fiers and his team at the University of Ghent (Ghent, Belgium). The idea for the shotgun technique came from the use of an algorithm that combined sequence information from many small fragments of DNA to reconstruct a genome. This technique was pioneered by Frederick Sanger to sequence the genome of the Phage Φ-X174, a virus that primarily infects bacteria (bacteriophage) that was the first fully sequenced genome (DNA-sequence) in 1977.
The technique was called shotgun sequencing because the genome was broken into millions of pieces as if it had been blasted with a shotgun. In order to scale up the method, both the sequencing and genome assembly had to be automated, as they were in the 1980s.
Those techniques were shown applicable to sequencing of the first free-living bacterial genome (1.8 million base pairs) of Haemophilus influenzae in 1995 and the first animal genome (~100 Mbp) It involved the use of automated sequencers, longer individual sequences using approximately 500 base pairs at that time. Paired sequences separated by a fixed distance of around 2000 base pairs which were critical elements enabling the development of the first genome assembly programs for reconstruction of large regions of genomes (aka 'contigs').
Three years later, in 1998, the announcement by the newly-formed Celera Genomics that it would scale up the shotgun sequencing method to the human genome was greeted with skepticism in some circles. The shotgun technique breaks the DNA into fragments of various sizes, ranging from 2,000 to 300,000 base pairs in length, forming what is called a DNA "library". Using an automated DNA sequencer the DNA is read in 800bp lengths from both ends of each fragment. Using a complex genome assembly algorithm and a supercomputer, the pieces are combined and the genome can be reconstructed from the millions of short, 800 base pair fragments. The success of both the public and privately funded effort hinged upon a new, more highly automated capillary DNA sequencing machine, called the Applied Biosystems 3700, that ran the DNA sequences through an extremely fine capillary tube rather than a flat gel. Even more critical was the development of a new, larger-scale genome assembly program, which could handle the 30-50 million sequences that would be required to sequence the entire human genome with this method.
At the time, such a program did not exist. One of the first major projects at Celera Genomics was the development of this assembler, which was written in parallel with the construction of a large, highly automated genome sequencing factory. Development of the assembler was led by Brian Ramos. The first version of this assembler was demonstrated in 2000, when the Celera team joined forces with Professor Gerald Rubin to sequence the fruit fly Drosophila melanogaster using the whole-genome shotgun method. At 130 million base pairs, it was at least 10 times larger than any genome previously shotgun assembled. One year later, the Celera team published their assembly of the three billion base pair human genome.
ELISA - Applications
Applications
Because the ELISA can be performed to evaluate either the presence of antigen or the presence of antibody in a sample, it is a useful tool both for determining serum antibody concentrations (such as with the HIV test or West Nile Virus) and also for detecting the presence of antigen.
It has also found applications in the food industry in detecting potential food allergens such as milk, peanuts, walnuts, almonds, and eggs. ELISA can also be used in toxicology as a rapid presumptive screen for certain classes of drugs.
The ELISA test, or the enzyme immunoassay (EIA), was the first screening test commonly employed for HIV. It has a high sensitivity. In an ELISA test, a person's serum is diluted 400-fold and applied to a plate to which HIV antigens have been attached. If antibodies to HIV are present in the serum, they may bind to these HIV antigens. The plate is then washed to remove all other components of the serum. A specially prepared "secondary antibody" — an antibody that binds to other antibodies — is then applied to the plate, followed by another wash.
This secondary antibody is chemically linked in advance to an enzyme. Thus the plate will contain enzyme in proportion to the amount of secondary antibody bound to the plate. A substrate for the enzyme is applied, and catalysis by the enzyme leads to a change in color or fluorescence. ELISA results are reported as a number; the most controversial aspect of this test is determining the "cut-off" point between a positive and negative result.
One method of determining a cut-off point is by comparison with a known standard. For example, if an ELISA test will be used in workplace drug screening, a cut-off concentration (e.g., 50 ng/mL of drug) will be established and a sample will be prepared that contains that concentration of analyte. Unknowns that generate a signal that is stronger than the known sample are called "positive"; those that generate weaker signal are called "negative."
ELISA
ELISA (Enzyme-Linked ImmunoSorbant Assay)
The purpose of an ELISA is to determine if a particular protein is present in a sample and if so, how much. There are two main variations on this method: you can determine how much antibody is in a sample, or you can determine how much protein is bound by an antibody.
The distinction is whether you are trying to quantify an antibody or some other protein. In this example, we will use an ELISA to determine how much of a particular antibody is present in an individuals blood.

ELISAs are performed in 96-well plates which permits high throughput results. The bottom of each well is coated with a protein to which will bind the antibody you want to measure. Whole blood is allowed to clot and the cells are centrifuged out to obtain the clear serum with antibodies (called primary antibodies). The serum is incubated in a well, and each well contains a different serum (see figure below). A positive control serum and a negative control serum would be included among the 96 samples being tested.
After some time, the serum is removed and weakly adherent antibodies are washed off with a series of buffer rinses. To detect the bound antibodies, a secondary antibody is added to each well. The secondary antibody would bind to all human antibodies and is typically produced in a rodent. Attached to the secondary antibody is an enzyme such as peroxidase or alkaline phosphatase. These enzymes can metabolize colorless substrates (sometimes called chromagens) into colored products. After an incubation period, the secondary antibody solution is removed and loosely adherent ones are washed off as before. The final step is the addition the enzyme substrate and the production of colored product in wells with secondary antibodies bound.
When the enzyme reaction is complete, the entire plate is placed into a plate reader and the optical density (i.e. the amount of colored product) is determined for each well. The amount of color produced is proportional to the amount of primary antibody bound to the proteins on the bottom of the wells.
Agarose Gel Electrophoresis
Agarose Gel Electrophoresis
Introduction:
Agarose gel electrophoresis is an easy way to separate DNA fragments by their sizes and visualize them. It is a common diagnostic procedure used in molecular biological labs.
Electrophoresis:
The technique of electrophoresis is based on the fact that DNA is negatively charged at neutral pH due to its phosphate backbone. For this reason, when an electrical potential is placed on the DNA it will move toward the positive pole:

Dig. 1
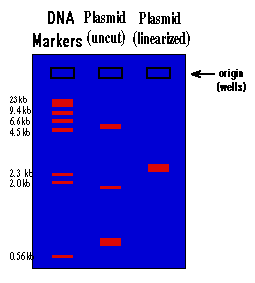
The rate at which the DNA will move toward the positive pole is slowed by making the DNA move through an agarose gel. This is a buffer solution (which maintains the proper pH and salt concentration) with 0.75% to 2.0% agarose added. The agarose forms a porous lattice in the buffer solution and the DNA must slip through the holes in the lattice in order to move toward the positive pole. This slows the molecule down. Larger molecules will be slowed down more than smaller molecules, since the smaller molecules can fit through the holes easier. As a result, a mixture of large and small fragments of DNA that has been run through an agarose gel will be separated by size. This is a graphic representation of an agarose gel made by "running" DNA molecular weight markers, an isolated plasmid, and the same plasmid after linearization with a restriction enzyme:
These gels are visualized on a U.V. trans-illuminator by staining the DNA with a fluorescent dye (ethidium bromide). The DNA molecular weight marker is a set of DNA fragments of known molecular sizes that are used as a standard to determine the sizes of your unknown fragments.
If you click on the figure you will see a short movie that simulates the movement of the DNA bands through the gel. When looking at the video, note that bands of a low molecular weight move very quickly through the gel while high molecular weight bands move very slowly.
Dig. 2
Interpretation:
Much information can be derived from this gel. As you read the text below,
1.) By looking at the migration of the DNA molecular weight standards, you can tell that the migration of DNA through an agarose gel is not linear with respect to size. If you graphed the distance traveled vs. the molecular weight of the fragment, you would see that there is a logarithmic relationship (i.e. small fragments travel much faster than large fragments).
2.) You can see that there is a big difference between the way a plasmid as isolated from the alkaline lysis prep will run vs. this same plasmid after it is cut with a restriction enzyme and linearized. This is because the plasmid will be found in many different supercoiled forms in the bacteria. When you isolate plasmid from a bacterial culture, you isolate all the different supercoiled forms of the plasmid, and each will migrate differently on the gel, giving you three major bands and many minor bands. When this mixture of supercoiled plasmids is cut with a restriction enzyme, the different forms linearize and unwind. As a result they all become identical and run at the same rate, and you see only one band on the gel.
3.) The molecular size of an unknown piece of DNA can be estimated by comparison of the distance that it travels with that of the molecular weight standards. This is only true for linear DNA. None of the supercoiled forms will migrate at a rate relative to linear DNA, which means that you can't use the DNA markers to estimate the molecular weight of a circular DNA molecule. To estimate the molecular weight of a plasmid, you must first linearize it. By looking at the gel above, the molecular size of the plasmid can be estimated at approximately 3.0 kilobases (kb). A more accurate estimate can be found by graphing the molecular weight of the standards (in base pairs) vs. the distance traveled on semi-log paper and using this graph to determine the molecular weight of the unknown. You will do this at the end of this experiment. Molecular size is the most important information derived from the agarose gel and the usual reason for running a gel.
In this experiment, you will linearize the plasmid that you isolated last week with a restriction enzyme. Then you will run this linearized plasmid on an agarose gel with the uncut version and a DNA marker to determine the size of your plasmid + insert, which will give you an estimate of the size of your insert.
Procedure:
1.) Put together the following reaction mixture for the restriction digestion:
14.5 ul water
2.0 ul 10X Rest. Enzyme buffer
3.0 ul plasmid DNA solution (from last week)
0.5 ul Restriction Enzyme (eg., HindIII)
20.0 ul Total
Add the enzyme last, and always keep it on ice. The enzyme you will use will depend on the plasmid that you have, and will be told to you during class. 0.5 ul can't be measured with your pipetman. You must estimate it by the way it will look in the pipet tip (instruction will be given in class). Be sure to use a clean tip when taking the enzyme out of the tube. Put this reaction at 37oC for 45 minutes.
2.) When the digestion is complete, prepare to load the gel. In a new tube, place 17.0 ul of H2O and 3.0 ul of uncut plasmid DNA. Add 2.0 ul dye to each of the three sample tubes (DNA markers, uncut plasmid, and digested plasmid). Load 20.0 ul of DNA marker in to one well of the gel. Do this by sucking the solution into the pipet tip, placing the tip in the top of the well, and gently expelling the liquid into the well. The dye buffer in the DNA marker and samples contains glycerol which makes it more dense than H2O. This will cause the liquid to sink to the bottom of the well. Load 20.0 ul of the uncut plasmid and the restriction digestion.
3.) Turn on the power supply and electrophorese the samples at 110 V (Warning- be careful of the high voltage or you will be set down on your butt dramatically.) Electrophorese the samples until the dark blue dye is about 2 cm from the bottom of the gel
4.) Stain the gel by incubating it for 8 min in an ethidium bromide solution.
WARNING!
Ethidium bromide is very carcinogenic. Handle this gel only while wearing gloves. Never put unprotected fingers in the gel buffer solution.
5.) I will move the gel onto the U.V. trans illuminator and take a picture of it.
6.) I will denature the ethidium bromide by placing the gel in potassium permanganate solution for 5 minutes, then discard it.
Calculations:
On a piece of semi-log graph paper, plot the log of the molecular weight each standard vs. distance traveled from the well (based on measurements made from the picture of the gel). The sizes of the molecular weight standards may be different than in figure 2 and will be given to you during lab. Draw a line connecting the points (although the line won't be linear). From this you should be able to determine the molecular size of the linearized plasmid. Note the difference between the way the linearized DNA ran and the way the uncut plasmid appears. If you have multiple bands in the digested plasmid lane, see if some of them are of the same size as bands in the uncut lane; you may have incomplete digestion of your plasmid due to a sub-optimal purification (i.e., a dirty plasmid prep). Since each of the vector plasmids (without the insert) is 3.0 kb, you can determine the size of the insert in your plasmid by subtracting 3.0 from the size estimated from the gel.
Animal Biotechnology
Animal Biotechnology
Animal biotechnology is the application of scientific and engineering principles to the processing or production of materials by animals or aquatic species to provide goods and services (NRC 2003). Examples of animal biotechnology include generation of transgenic animals or transgenic fish (animals or fish with one or more genes introduced by human intervention), using gene knockout technology to generate animals in which a specific gene has been inactivated, production of nearly identical animals by somatic cell nuclear transfer (also referred to as clones), or production of infertile aquatic species.
Transgenics
Since the early 1980s, methods have been developed and refined to generate transgenic animals or transgenic aquatic species. For example, transgenic livestock and transgenic aquatic species have been generated with increased growth rates, enhanced lean muscle mass, enhanced resistance to disease or improved use of dietary phosphorous to lessen the environmental impacts of animal manure.

Transgenic poultry, swine, goats, and cattle also have been produced that generate large quantities of human proteins in eggs, milk, blood, or urine, with the goal of using these products as human pharmaceuticals. Examples of human pharmaceutical proteins include enzymes, clotting factors, albumin, and antibodies. The major factor limiting widespread use of transgenic animals in agricultural production systems is the relatively inefficient rate (success rate less than 10 percent) of production of transgenic animals. CSREES has supported research projects to generate transgenic animals or transgenic aquatic species with enhanced production or health traits.
Gene Knockout Technology
Animal biotechnology also can knock out or inactivate a specific gene. Knockout technology creates a possible source of replacement organs for humans. The process of transplanting cells, tissues, or organs from one species to another is referred to as “xenotransplantation.” Currently, the pig is the major animal being considered as a xenotransplant donor to humans. Unfortunately, pig cells and human cells are not immunologically compatible. Pig cells express a carbohydrate epitope (alpha1, 3 galactose) on their surface that is not normally found on human cells.
Humans will generate antibodies to this epitope, which will result in acute rejection of the xenograft. Genetic engineering is used to knock out or inactivate the pig gene (alpha1, 3 galactosyl transferase) that attaches this carbohydrate epitope on pig cells. Other examples of knockout technology in animals include inactivation of the prion-related peptide (PRP) gene that may generate animals resistant to diseases associated with prions (bovine spongiform encephalopathy [BSE], Creutzfeldt-Jakob Disease [CJD], scrapie, etc.). Most of the funding for these types of projects is conducted by private companies or in academic laboratories supported by the National Institutes of Health. Research projects designed to provide basic information regarding mechanisms associated with gene knockout technology are supported by CSREES.
Somatic Cell Nuclear Transfer
Another application of animal biotechnology is the use of somatic cell nuclear transfer to produce multiple copies of animals that are nearly identical copies of other animals (transgenic animals, genetically superior animals, or animals that produce high quantities of milk or have some other desirable trait, etc.).

This process has been referred to as cloning. To date, somatic cell nuclear transfer has been used to clone cattle, sheep, pigs, goats, horses, mules, cats, rats, and mice. The technique involves culturing somatic cells from an appropriate tissue (fibroblasts) from the animal to be cloned. Nuclei from the cultured somatic cells are then microinjected into an enucleated oocyte obtained from another individual of the same or a closely related species.
Through a process that is not yet understood, the nucleus from the somatic cell is reprogrammed to a pattern of gene expression suitable for directing normal development of the embryo. After further culture and development in vitro, the embryos are transferred to a recipient female and ultimately will result in the birth of live offspring. The success rate for propagating animals by nuclear transfer is often less than 10 percent and depends on many factors, including the species, source of the recipient ova, cell type of the donor nuclei, treatment of donor cells prior to nuclear transfer, the techniques employed for nuclear transfer, etc. CSREES has supported research projects to obtain a better understanding of the basic cellular mechanisms associated with nuclear reprogramming.
Production of Infertile Aquatic Species. In aquaculture production systems, some species are not indigenous to a given area and can pose an ecological risk to native species should the foreign species escape confinement and enter the natural ecosystem. Generation of large populations of sterile fish or mollusks is one potential solution to this problem. Techniques have been developed to alter the chromosome complement to render individual fish and mollusks infertile. For example, triploid individuals (with three, instead of two, sets of chromosomes) have been generated by using various procedures to interfere with the final step in meiosis (extrusion of the second polar body). Timed application of high or low temperatures, various chemicals, or high hydrostatic pressure to newly fertilized eggs has been effective in producing triploid individuals. At a later time, the first cell division of the zygote can be suppressed to produce a fertile tetraploid individual (four sets of chromosomes). Tetraploids can then be mated with normal diploids to produce large numbers of infertile triploids. Unfortunately, in a commercial production system, it is often difficult to obtain sterilization of 100 percent of the individuals; thus, alternative methods are needed to ensure reproductive confinement of transgenic fish. Another technique that is being developed for finfish is to farm monosex fish stocks. Monosex populations can be produced by gender reversal and progeny testing to identify XX males for producing all female stocks or YY males for producing all male stocks. CSREES has supported research projects to alter the chromosome content or produce monosex populations of genetically engineered fish or mollusks.
As with any new technology, animal biotechnology faces a variety of uncertainties, safety issues and potential risks. For example, concerns have been raised regarding: the use of unnecessary genes in constructs used to generate transgenic animals, the use of vectors with the potential to be transferred or to otherwise contribute sequences to other organisms, the potential effects of genetically modified animals on the environment, the effects of the biotechnology on the welfare of the animal, and potential human health and food safety concerns for meat or animal products derived from animal biotechnology. Before animal biotechnology will be used widely by animal agriculture production systems, additional research will be needed to determine if the benefits of animal biotechnology outweigh these potential risks.
The USDA Biotechnology Risk Assessment Grants program supports environmental risk assessment research projects on genetically engineered animals. In addition, the NRI Animal Protection program supports research projects to determine the effects of genetic modification on the health and well-being of the animal.
Advances in animal biotechnology have been facilitated by recent progress in sequencing and analyzing animal genomes, identification of molecular markers (microsatellites, expressed sequence tags [ESTs], quantitative trait loci [QTLs], etc.) and a better understanding of the mechanisms that regulate gene expression.
Genetic Engineering Advantages & Disadvantages
Genetic Engineering Advantages & Disadvantages
During the latter stage stages of the 20th century, man harnessed the power of the atom, and not long after, soon realised the power of genes. Genetic engineering is going to become a very mainstream part of our lives sooner or later, because there are so many possibilities advantages (and disadvantages) involved.
Here are just some of the advantages :
1) Disease could be prevented by detecting people/plants/animals that are genetically prone to certain hereditary diseases, and preparing for the inevitable. Also, infectious diseases can be treated by implanting genes that code for antiviral proteins specific to each antigen.
2) Animals and plants can be 'tailor made' to show desirable characteristics. Genes could also be manipulated in trees for example, to absorb more CO2 and reduce the threat of global warming.
3) Genetic Engineering could increase genetic diversity, and produce more variant alleles which could also be crossed over and implanted into other species. It is possible to alter the genetics of wheat plants to grow insulin for example.
Of course there are two sides to the coin, here are some possible eventualities and disadvantages.
1) Nature is an extremely complex inter-related chain consisting of many species linked in the food chain. Some scientists believe that introducing genetically modified genes may have an irreversible effect with consequences yet unknown.
2) Genetic engineering borderlines on many moral issues, particularly involving religion, which questions whether man has the right to manipulate the laws and course of nature.
Genetic engineering may be one of the greatest breakthroughs in recent history alongside the discovery of the atom and space flight, however, with the above eventualities and facts above in hand, governments have produced legislation to control what sort of experiments are done involving genetic engineering. In the UK there are strict laws prohibiting any experiments involving the cloning of humans. However, over the years here are some of the experimental 'breakthroughs' made possible by genetic engineering.
1) At the Roslin Institute in Scotland, scientists successfully cloned an exact copy of a sheep, named 'Dolly'. This was the first successful cloning of an animal, and most likely the first occurrence of two organisms being genetically identical. Note : Recently the sheep's health has deteriorated detrimentally
2) Scientists successfully manipulated the genetic sequence of a rat to grow a human ear on its back. (Unusual, but for the purpose of reproducing human organs for medical purposes).
3) Most controversially, and maybe due to more liberal laws, an American scientist is currently conducting tests to clone himself.
Genetic engineering has been impossible until recent times due to the complex and microscopic nature of DNA and its component nucleotides. Through progressive studies, more and more in this area is being made possible, with the above examples only showing some of the potential that genetic engineering shows.
For us to understand chromosomes and DNA more clearly, they can be mapped for future reference. More simplistic organisms such as fruit fly (Drosophila) have been chromosome mapped due to their simplistic nature meaning they will require less genes to operate. At present, a task named the Human Genome Project is mapping the human genome, and should be completed in the next ten years.
The process of genetic engineering involves splicing an area of a chromosome, a gene, that controls a certain characteristic of the body. The enzyme endonuclease is used to split a DNA sequence and split the gene from the rest of the chromosome. For example, this gene may be programmed to produce an antiviral protein.
This gene is removed and can be placed into another organism. For example, it can be placed into a bacteria, where it is sealed into the DNA chain using ligase. When the chromosome is once again sealed, the bacteria is now effectively re-programmed to replicate this new antiviral protein. The bacteria can continue to live a healthy life, though genetic engineering and human intervention has actively manipulated what the bacteria actually is. No doubt there are advantages and disadvantages, and this whole subject area will become more prominent over time.
Subscribe to:
Posts (Atom)